4.1 Verschiedene Arten von Conversion-Rates
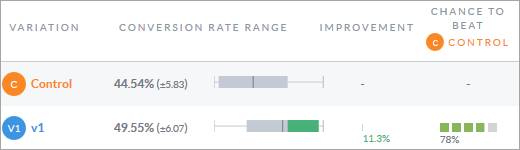
Dies scheint auf den ersten Blick offensichtlich: Ins Webanalyse-Tool geschaut. Die Conversion-Rate nachgeschaut. Fertig.
Seitenübergreifende Conversion-Rate in Google Analytics
Dieser Wert ist aus zwei Gründen jedoch häufig nicht passend:
- In vielen Fälle läuft der Test nicht auf allen Seiten. Es wird also nicht die seitenübergreifende, sondern die Conversion-Rate der zu testenden Seite benötigt.
- Diese Conversion-Rate basiert auf Besuchen (ohne „r“). A/B-Tests arbeiten jedoch meistens mit Besuchern (mit „r“) im Nenner. Mit anderen Worten: Testteilnehmer müssen sich beim ersten Besuch konvertieren.
Zumindest bei Google Analytics sind Besucher, auch „Sessions“ genannt, im Nenner.
Wie berechnet man also die testspezifische Conversion-Rate? Die Definition der Conversion-Rate lautet: Anzahl Conversions / Anzahl Besucher. Diese beiden Werte schreiben wir nun näher.
4.2 Anzahl Besucher
Bestimmen Sie zuerst die Anzahl der wahrscheinlich am Test teilnehmenden Besucher. Wird der Test auf allen Seiten laufen, schauen Sie in Google Analytics im Bericht Zielgruppe > Übersicht nach.
Wir gehen hier davon aus, dass es zwischen dem aktuell im Webanalyse-Tool ausgewählten Zeitraum und dem tatsächlichen Testzeitraum keine signifikanten Schwankungen gibt. Wegen der Weihnachtszeit können die meisten Händler
den Dezember beispielsweise nicht mit dem Januar vergleichen. Aber auch Werbekampagnen beeinflussen die Anzahl der Testteilnehmer.
Passen Sie die Zahlen im Webanalyse-Tool entsprechend an oder wählen den geplanten Testzeitraum im vorigen Jahr (falls es seit diesem Zeitraum nicht schon zu großen Veränderungen der Conversions und Besucher gekommen ist).
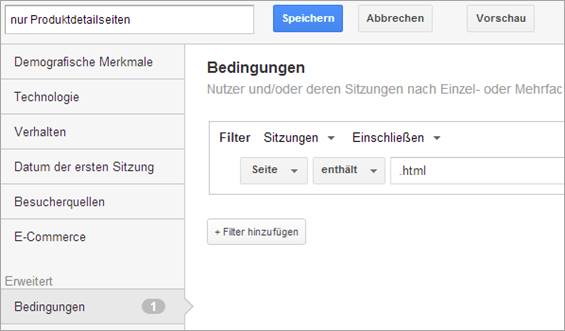
Wird der Test nur auf bestimmten Seiten, beispielsweise nur Produktdetailseiten, laufen, dann erstellen Sie ein Segment wie dieses:
Wir gehen davon aus, dass man Produktdetailseiten daran identifizieren kann, dass sie als einzige Seiten mit „.html“ enden. Finden Sie für Ihre Website ein analoges Kriterium. Der Praxisguide „Seiten sinnvoll gruppieren“ gibt eine konkrete Anleitung hierzu.
Wenden Sie dieses Segment auf den Bericht Zielgruppe > Übersicht an und notieren die Anzahl der Nutzer.
4.3 Anzahl Conversion
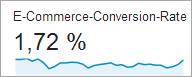
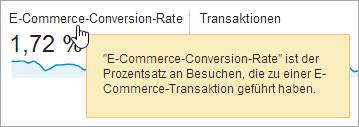
Bei einem seitenübergreifenden Test verwenden Sie die Gesamtzahl der Conversions. Falls es sich um eine E-Commerce-Transaktion handelt, schauen Sie in Google Analytics unter Conversions > E-Commerce > Übersicht nach.
Für Tests bestimmter Seiten wenden Sie das im vorigen Unterkapitel beschriebene Segment auf genau diesen Bericht an und notieren Sie die Anzahl.
Nun können Sie die aktuelle testspezifische Conversion-Rate berechnen. Tragen Sie diese Zahl nun in den Rechner ein. Denken Sie daran, einen Punkt als Dezimaltrennzeichen zu verwenden.
5. Anzahl Testteilnehmer und Dauer des Tests
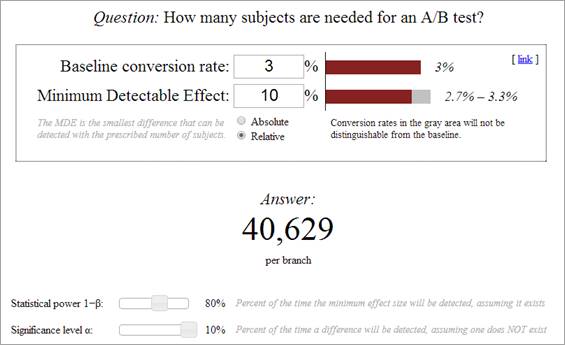
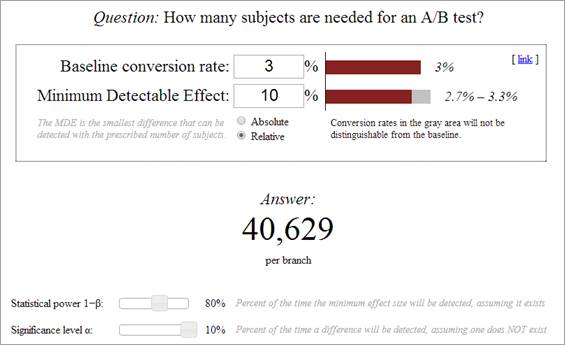
Nachdem die beiden Werte eingegeben und die Schieberegler eingestellt sind, zeigt das Tool an, wie viele Testteilnehmer für dieses Szenario benötigt werden.
In unserem Beispiel werden 40.629 Testteilnehmer pro Variante benötigt. Da die Kontrollvariante auch Teil des Tests ist, werden also für einen Test mit einer Variante 81.258 Testteilnehmer benötigt.
Basierend auf der Anzahl der voraussichtlichen Testteilnehmer aus Kapitel 4.3 können Sie nun einschätzen, wie lange der Test laufen wird.
Wird der Test wahrscheinlich nur zwei Wochen dauern, dann fügen Sie noch eine weitere Testvariante hinzu. Berechnen Sie dann, wie lange ein Test mit Kontrollvariante plus zwei Varianten dauern würde.
Wird der Test mit nur einer Testvariante schon 6 Wochen dauern, dann belassen Sie es bei nur einer Testvariante.