Seit über 10 Jahren führen wir A/B-Tests durch. Für Kunden aus allen Branchen und mit allen Geschäftsmodellen: Shops, Lead-Generierung, Portale, Subscription und SaaS.
Dadurch blicken wir über den Tellerrand Ihrer Branche und liefern laufend frische Testkonzepte.
Kein reines Vertriebsgespräch, ehrliche Beratung zu Ihren nächsten Schritten
A/B-Testing mit uns heißt...
Research + Daten = erfolgreiches A/B-Testing
Wir generieren individuelle Testhypothesen, basierend auf Webanalyse-Daten und qualitativem Research. Wir setzen auf Daten statt Bauchgefühl und Meinung.
A/B-Testing Tool inklusive
Wenn gewünscht, bringen wir ein professionelles A/B-Testing Tool mit - ohne hohe Extrakosten. Ansonsten arbeiten wir gern mit vorhandenen Tools.
Faire Konditionen, ohne lange “Knebelverträge”
Monatlich kündbar: Wir überzeugen durch kontinuierliche Leistungen und Engagement, nicht durch Verträge.
Optional mit Programmierung der A/B-Tests
Gerne arbeiten wir mit vorhandenen Entwicklern zusammen. Wenn gewünscht, übernehmen wir schnell und effizient die Programmierung der A/B-Tests.
Für wen ist A/B-Testing sinnvoll - und für wen nicht?
Beim A/B-Testing möchte man unbedingt ausschließen, dass Steigerungen der Conversion-Rate im Test nur zufällig zustande gekommen sind. Stattdessen soll die Steigerung auch bestehen bleiben, sobald die Gewinnervariante allen Besuchern ausgespielt wird.
Je höher die Anzahl der gemessenen Conversions, desto besser die Chancen, statistisch signifikante Ergebnisse zu erzielen - und so nur zufällig bessere Testergebnisse zu vermeiden.
Wie viele Verkäufe bzw. Conversions brauche ich für A/B-Testing?
Ab 1.000 Conversions je Monat ist A/B-Testing sinnvoll. Dann können mehrere Tests je Monat durchgeführt werden und schneller Erfolge gesammelt werden.
Wichtig: Es müssen mindestens 1.000 gemessene Conversions (wie Verkäufe im Shop oder Leads) vorhanden sein. Diese Zahl kann deutlich geringer sein als die Zahl im CRM oder Shopsystem. Fehlender Consent und Adblocker führen häufig dazu, dass viele Conversions im Testing-Tool nicht gemessen werden.
Bei weniger als 1.000 gemessenen Conversions ist A/B-Testing schwierig. Tests müssen lange laufen und führen häufig zu keinem Ergebnis.
Eine häufige Idee: Statt dem Verkauf einfach Mikro-Conversions wie “Produkt zum Warenkorb hinzugefügt” als Metrik im A/B-Test nehmen. Weitere Möglichkeiten sind “X Sekunden auf der Seite” oder “X% gescrollt”.
Leider gibt es meistens keinen Zusammenhang zwischen solchen Mikro-Conversions und der finalen Conversion, die wirklich zu Umsatz führt. A/B-Tests auf Mikro-Conversions sind deshalb nicht sinnvoll.
Trotzdem sollten Mikro-Conversions in A/B-Tests gemessen werden, um den Einfluss der Testvariante besser zu verstehen.
A/B-Testing mit wenig Conversions / Verkäufen
In diesem Fall ist eine Optimierung basierend auf qualitativen Methoden, einem guten Verständnis der Besucher sowie deren Problemen und der Vorteile des Angebots die bessere Wahl. Wir bieten dies mit unserem Website-Konzept an.
Unsere Einschätzung
Wenn A/B-Tests nur mit Micro-Conversions funktionieren würden, sollte man lieber andere Methoden zur Conversion-Optimierung einsetzen.
Insbesondere qualiative Methoden wie Session-Recordings, Onsite-Umfragen, mit Stakeholdern sprechen oder Best-Practice-Optimierungen sind sinnvoll.
Wie funktioniert A/B-Testing technisch?
Das Grundprinzip ist einfach: Besuchern wird zufällig eine Testvariante (oder die Kontrollvariante) zugewiesen und nach einer bestimmten Zeit überprüft, ob dies zu mehr Conversion geführt hat. Analog zu einer medizinischen Studie.
Client-seitiges Testing vs. Server-seitiges Testing
Client-seitiges Testing
Die Testvariante wird im Browser erzeugt, die bestehende Seite wird per JavaScript “on the fly” angepasst.
Testing unabhängig von Releases und IT
Oft schnellere / mehr Tests möglich
Flackern, wenn nicht gut integriert
Weniger Teilnehmer durch AdBlocker und fehlenden Consent
Server-seitiges Testing
Die Testvariante wird schon auf dem Server erstellt und als fertiges HTML an den Browser übermittelt.
Mehr Testteilnehmer
Konsistentere Variantenzuweisung
Kein Flackern
Technisch viel komplexer
Mehr Abstimmung und Ressourcen erforderlich
Die Client-seitige Variante hat den großen Vorteil, dass keine Absprache mit Webentwicklern notwendig ist. Die Testvariante kann unabhängig von Releases erstellt (zum Beispiel von einer externen Agentur) und der Test gestartet werden. Gerade in großen Unternehmen verlangsamt das den Testing-Prozess.
Es gibt jedoch auch zwei große Nachteile der Client-seitigen Variante:
Es gibt häufig ein Flackern. Besucher sehen für kurze Zeit die normale Seite, während die Testvariante per JavaScript umgebaut wird.
Durch AdBlocker und fehlenden Consent nehmen nicht alle Besucher an Tests teil. A/B-Tests müssen länger laufen und es ist schwieriger, statistisch signifikante Ergebnisse zu erzielen.
Beim Server-seitigen Testing ist die Situation vertauscht:
Vorteile: Es gibt kein Flackern und keine Probleme mit Adblocker/fehlendem Consent.
Nachteil: Es braucht erfahrene Webentwickler und viel Planung, um Tests zu starten. In den meisten Unternehmen ist dies nicht der Fall. Deshalb werden fast alle Tests Client-seitig durchgeführt.
A/B-Test per Weiterleitung oder DOM-Manipulation umsetzen?
Client-seitige Tests können auf zwei verschiedene Arten umgesetzt werden:
per DOM-Manipulation: Per JavaScript wird die bestehende Seite live umgebaut.
per Weiterleitung: Besuchern, welchen eine Testvariante zugewiesen wird, werden auf eine separate URL weitergeleitet.
In den meisten Fällen kommt die DOM-Manipulation zum Einsatz. Gründe dafür sind:
Die Anpassung der Seite ist weniger sichtbar als eine komplette Weiterleitung (und meistens auch schneller).
Sollen mehrere Seiten (zum Beispiel alle Produktseiten) getestet werden, ist eine Weiterleitung nicht möglich. Es müssten sehr viele verschiedene Produktseiten erstellt werden.
A/B-Tests mit dem WYSIWYG- oder Drag-and-Drop-Editor erstellen
Viele A/B-Testing-Tools werden mit einem Drag-and-Drop-Editor (auch “What you see is what you get” - kurz WYSIWYG - genannt). Mit diesem können Marketer man angeblich Testvarianten ohne JavaScript-Kenntnisse selbst erstellen.
In der Realität funktioniert dies nur selten. Es klappt insbesondere nicht, wenn …
Änderungen auf Template-Ebene (zum Beispiel der Produktseite) vorgenommen werden
bestehende JavaScript-Funktionalitäten angepasst werden
größere Änderungen vorgenommen werden
Die Drag-and-Drop-Editoren eignen sich bestenfalls für leichte Anpassungen von Texten und Farben auf Landingpages oder zum Ausblenden von Bereichen.
In den meisten Fällen müssen client-seitige A/B-Tests deshalb in JavaScript programmiert werden.
Unsere Einschätzung
Die Editoren der Tools helfen in der Praxis nur sehr selten weiter. A/B-Testing ist ohne manuelle Programmierung kaum möglich.
1. Erfolgversprechende Ansätze für A/B-Tests finden
Für langfristig erfolgreiche A/B-Tests braucht man einen guten und strukturierten Prozess, um immer wieder erfolgversprechende Ansätze und Testideen zu finden.
In vielen Unternehmen werden einfach die Dinge getestet, von denen jemand denkt, dass es einen Einfluss haben könnte (“Lass uns mal den Button farbig machen…”, “Ich habe bei Zalando gesehen, dass…”).
Das führt nur selten zum Erfolg - wenn doch, ist der Ablauf nicht reproduzierbar. Viele Testideen, die ohne gezielte Ideensuche zustande kommen, scheitern - und damit oft das ganze Thema A/B-Testing.
Aber welche Datenquellen lassen sich nutzen, um systematisch und laufend neue Ideen für A/B-Tests zu finden?
Mit Onsite-Umfragen Ideen für A/B-Tests finden
Onsite-Umfragen sind ein einfaches, aber gleichzeitig mächtiges Mittel, um die Motivationen von Besuchern zu verstehen. Unterschiedliche Motivationen sind häufig gute Ansatzpunkte für A/B-Testing-Ideen.
Bei unseren Kunden läuft immer eine (wechselnde) Umfrage auf der Vielen-Dank-Seite. Und häufig auch auf dem Rest der Website (wie im Warenkorb die Frage “Was hält dich vom Kauf ab?”).
Wir fragen auf der Vielen-Dank-Seite beispielsweise, was Besucher besonders überzeugt hat. Sowohl bezogen auf die Produkte als auch den Shop selbst. Diese Informationen werden im A/B-Test prominenter dargestellt (häufig in einer eigenen Box auf der Produktseite).
Beispiele hierfür sind
Produkte sind Made in Germany
Produkte werden nachhaltig hergestellt
Es sind nur natürliche Inhaltsstoffe enthalten
Hilfreiche Beratung (inkl. echtem Foto der Berater)
Der Wettbewerb besteht nicht nur aus direkten Wettbewerbern, sondern kann auch eine andere Lösung für das gleiche Problem sein. Zudem ist es hilfreich, in anderen Ländern wie den USA und UK zu recherchieren.
Im zweiten Schritt prüft man, was Wettbewerber anders machen. Der Fokus sollte wirklich auf "anders machen" liegen, nicht auf "besser machen". Von außen ist dies häufig schwierig zu beurteilen.
In einem Google Sheet sammeln wir alle Ideen mit URLs und Screenshots.
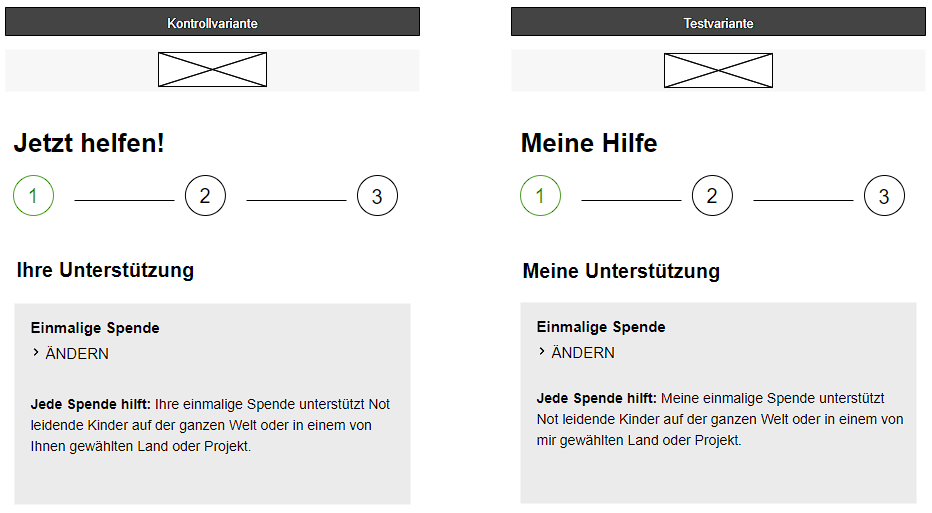
Zum Beispiel haben wir bei einem anderen Non-Profit entdeckt, dass im Spendenprozess aus der Ich-Perspektive kommuniziert wird. Dies hat zu einem signifikanten Uplift geführt.
A/B-Test: Die Formulierung aus der Ich-Perspektive führt zu signifikant mehr Spenden.
Datenbank früherer A/B-Tests nutzen
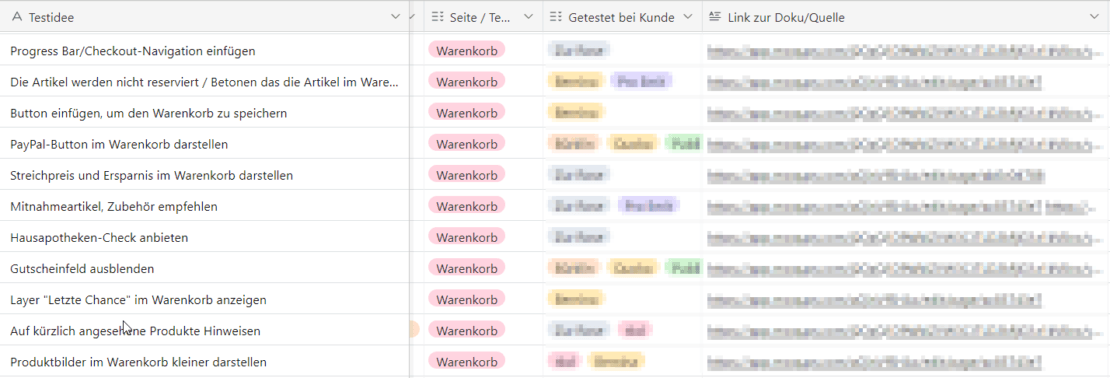
Basierend auf allen unserer bisher durchgeführten A/B-Tests haben wir eine umfangreiche Datenbank von potenziellen Testideen.
Natürlich wählen wir nicht blind irgendeine Testidee aus, sondern prüfen, was bei ähnlichen Kunden schon funktioniert hat. Ähnlichkeit kommt nicht nur über die gleiche Branche, sondern auch über Attribute wie
Geht es um ein langes Commitment?
Geht es um sensible Daten?
Ist der Kauf eher emotional oder rational?
Ausschnitt unserer Datenbank sinnvoller Testideen in Airtable
Expertenanalyse in der Gruppe
Optimiert man schon länger eine Website/Projekt, ist man häufig zu tief drin. Es ist schwierig, die Sicht eines Besuchers einzunehmen, der zum ersten Mal kommt.
Um frischen Wind in ein Projekt zu bringen, analysieren wir in der Gruppe (mit ca. 5 Personen), jeweils einen Seitentyp. Innerhalb dieser Gruppe gibt es Personen, die sich schon länger mit dem Projekt befassen und Personen, die das Projekt (fast) nicht kennen.
Diese Fragen stellen wir uns:
Weshalb und wie kommen Besucher auf die Seite? Was sind ihre Erwartungen?
Welche Informationen benötigen Besucher?
Ist es für die Zielgruppe verständlich/klar, was angeboten wird?
Ist die Argumentation überzeugend? Werden Besucher motiviert, zu konvertieren?
Welches Ziel verfolgt die Seite? Was sind die nächsten Schritte? Was muss sie dafür tun?
Gibt es zu viel Ablenkung?
Vertrauen Besucher der Seite?
Was macht es kompliziert, die Seite zu bedienen?
In relativ kurzer Zeit (ca. 1 Stunde) findet man so strukturiert neue Testideen.
Wenn ein Test zum Thema X einen positiven Einfluss hatte, dann lohnt es sich, das Thema weiterzuentwickeln.
In einem Test auf der Produktseite haben initial ausgeklappte Produktbewertungen zu einer Conversion-Rate-Steigerung geführt.
Unsere Nachfolgetests:
Bewertungen auf der Produktseite noch prominenter anzeigen. Zum Beispiel mit einer farbigen Box und dem Hinweis “xx% würden das Produkt weiterempfehlen”.
Ausgewählte Bewertungen auch auf der Kategorieseite anzeigen. Zum Beispiel als eine weitere Kachel im Produktlisting.
Damit man auch bei vielen Tests den Überblick behält, sollte man alle A/B-Tests in Themen einteilen. Diese können sein: Preiskommunikation, Vorteilskommunikation, Entscheidung/Hilfestellung/Führung, Wahrnehmung, Vertrauen, Verständlichkeit.
Nachfolgetest mit Bewertungen auf der Kategorieseite
2. Testvarianten konzipieren - darauf kommt es an
Nachdem man eine gute Testidee identifiziert hat, muss diese als Nächstes als Hypothese formuliert werden.
Diese Hypothese sollte das erhoffte Ziel beinhalten, z.B. “Wenn wir Änderung X vornehmen, dann werden die Transaktionen steigen, weil sich Nutzer leichter zurechtfinden”. Mithilfe dieser Hypothese kann man dann eine entsprechende Testvariante konzipieren, in welcher diese Änderung klar dargestellt werden sollten.
Varianten für A/B-Test müssen sich deutlich unterscheiden
Häufig haben Testvarianten nicht den gewünschten oder keinerlei Einfluss.
Grund dafür ist meistens, dass der Unterschied zwischen Test- und Kontrollvariante zu klein ist. Denn kleine Unterschiede haben meistens auch nur einen geringen Einfluss auf das Besucherverhalten. Um statistisch signifikante Ergebnisse zu erzielen, muss der Unterschied zwischen den Testvarianten auch genügend groß sein.
Soll zum Beispiel Social Proof hervorgehoben werden, dann sollte das passende Element gut sichtbar positioniert werden. Am besten im sofort sichtbaren Bereich, statt weiter unten in einem Akkordeon versteckt.
Große Unterschiede sind jedoch nicht nur visuell, sondern auch inhaltlich. Beispielsweise kann man in einer Testvariante erproben, ob die Argumentation “Mehr Umsatz machen” oder “Weniger Zeit investieren” für eine Software besser überzeugt. Formulierungen müssen sich auf den ersten Blick unterscheiden.
Um kontrastreiche Testvarianten zu testen, braucht es Mut. Vor allem, wenn es Bedenken von Anderen gibt. Hier muss Überzeugungsarbeit geleistet werden, dass man nicht “erst mal nur was Kleines” testen sollte. In den meisten Fällen führt dies zu Tests ohne Einfluss und zum Gefühl, dass A/B-Tests nichts bringen. Dadurch kommen die Testvarianten, die tatsächlich etwas bewegen können, oft gar nicht mal an die Reihe.
Bei der Konzeption an alle Möglichkeiten und Ausprägungen denken
Vor allem in Online-Shops werden nicht einzelne Seiten getestet, sondern es wird auf Basis von Templates getestet. Templates sind z.B. die Produktseite, Kategorieseite, usw. Die Testvariante muss daher für alle Produkte funktionieren.
Damit man später bei der Programmierung oder Qualitätssicherung kein böses Erwachen erlebt, muss man schon bei der Konzeption die verschiedenen Ausprägungen berücksichtigen. Am besten erstellt man eine Übersicht, wie sich einzelne Seiten eines Templates unterscheiden können.
Unterschiedliche Ausprägungen können sein:
Überschriften sind manchmal eine Zeile, manchmal zwei Zeilen lang
Manche Produkte sind Sets, die anders dargestellt werden als normale Produkte
Manche Kategorieseiten haben standardmäßig eine Listenansicht, andere eine Kachelansicht.
Manche Produktseiten verfügen über alternative Produkte, andere haben Cross-Sells, andere gar keine Produktempfehlungen.
Es gibt verschiedene Produktvarianten
Unterschiedliche Darstellung der Preise und Rabatte
Produktseiten mit zusätzlichen Inhalten wie Videos
Wenn immer man eine Testvariante konzipiert, nimmt man die Liste zur Hand und prüft, ob man die Testvariante gegebenenfalls anpassen muss.
Varianten mit echten Texten und Bildern erstellen
Beispieltexte oder Platzhalter (wie “lorem Ipsum”) haben in Testvarianten nichts zu suchen. Es sollten ausschließlich echte Überschriften, Texte, Aufzählungen und Bilder verwendet werden.
Nur so kann man prüfen, ob das Konzept wie angedacht funktioniert. Insbesondere, ob der Kontrast zwischen der Kontroll- und der Testvariante hoch genug ist.
Das Briefing bestimmt Qualität und Dauer der Umsetzung
Nicht alle Testvarianten muss man genau, wie im Konzept angedacht, umsetzen. Damit man nah drankommt, braucht es ein gutes Briefing. Wichtige Punkte sind:
Kommunizieren, wo Freiraum besteht - und wo nicht: Durch den Wireframe vorgegeben sind zum Beispiel die vorhandenen Elemente, Formulierungen für Texte sowie Anordnung und Größe der Elemente. Kreativer Freiraum besteht hingegen bei Formen wie Boxen und Rahmen, Störern oder bei den verwendeten Farben.
Wireframes für Desktop und Mobile getrennt: Wie Elemente auf den einzelnen Geräteklassen konzipiert sind, sollte nicht dem Designer/Entwickler überlassen werden, sondern klar in der Testvariante definiert sein. Daher sollte man auch immer Wireframes für Desktop und Mobile erstellen.
Informationen auf einmal senden: Unnötige Schleifen sind nervig. Stattdessen sollten alle notwendigen Informationen auf einmal gesendet werden.
zu verwendende Bilder oder URLs der Bilder (in richtiger Auflösung)
Testvarianten programmieren und Testing-Tool konfigurieren
1) Gutes Briefing des A/B-Tests für Entwickler verfassen
Wichtigste Voraussetzung für die Programmierung ist ein gutes Briefing. Dieses beschreibt genau,
worin die Motivation des Tests besteht
welche Veränderungen in der Testvarianten vorgenommen werden
auf welche Unterschiede innerhalb einem Seitentyp geachtet werden muss (auf manchen Produktseiten gibt es zum Beispiel zwei Arten von Produktempfehlungen, auf anderen nur eine)
was passiert, wenn man auf ein interaktives Element klickt
welches zusätzliche Tracking aufgesetzt werden soll
Zusätzlich zum Wireframe werden alle benötigten Informationen wie Linkziele oder Bilder direkt mitgeschickt.
Auf diese Weise minimiert man die benötigten Rückfragen, denn diese werden im Briefing alle direkt beantwortet. Mit einem guten Briefing erhält man vom Entwickler dann direkt den JavaScript-Code. Fertig.
2) Testvarianten in JavaScript und HTML umsetzen
Die visuellen Editoren der Testing-Tools sind nur bei sehr einfachen Tests sinnvoll. Die meisten Tests sollten daher besser “von Hand” programmiert werden.
Wichtigstes Ziel
Flackern so gering wie möglich halten. (Die normale Website wird für kurze Zeit sichtbar.)
Visuelle Änderungen dafür per CSS, nicht per JavaScript umsetzen. Denn, damit CSS-Änderungen aktiv sind, muss das HTML-Element noch gar nicht verfügbar sein.
Wenn man JavaScript-Code einsetzt, um ein Element einzufügen oder zu bearbeiten, dann immer prüfen, ob das Element (schon) verfügbar ist. Sonst läuft die Änderung “ins Leere”.
Der Code-Editor im Testingtool
Weitere Best Practices:
Einzelne Schritte im Code kommentieren, damit auch andere damit arbeiten können.
Immer auch direkt das Tracking aufsetzen. Zum Beispiel, Klicks auf neu eingefügte Buttons.
Alle Besonderheiten, die beim Programmieren aufkommen, in der Dokumentation festhalten
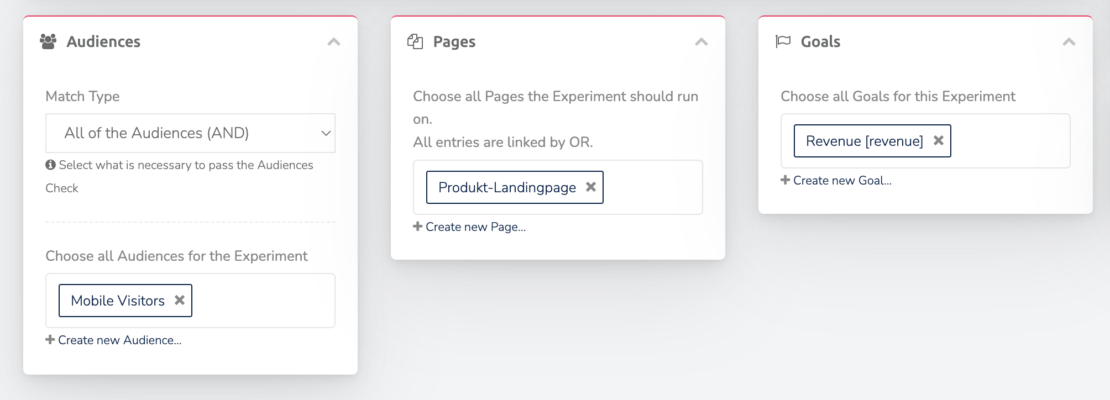
3) Targeting im Testing-Tool konfigurieren
Es müssen zwei Arten von Targeting eingestellt werden:
Auf welchen Seiten/Templates soll der Test laufen?
Welche Nutzer sollen den Test sehen (nur eine Traffic-Quelle, nur Mobile, für wiederkehrende Besucher)?
Im Idealfall kommen alle diese Informationen aus dem dataLayer. In dieser JavaScript-Variable sollte unter anderem bereitgestellt werden:
Seitentyp
Ist der Besucher eingeloggt?
Hat der Besucher schon mal gekauft?
Soll man erst bei einem bestimmten Ereignis (wie add_to_cart) am Test teilnehmen, dann muss dieses Ereignis auch im dataLayer stehen.
Gleiches gilt für Tests auf Single Page Applications oder Checkouts, bei denen sich die URL zwischen den Schritten nicht ändert. Auch hier ist ein befüllter dataLayer unabdinglich.
Das Targeting der Testvariante im Testingtool einstellen
4. Systematische Qualitätssicherung von Testvarianten - Fehler systematisch finden
Qualitätssicherung der Testvariante: notwendige Voraussetzung für aufschlussreiche A/B-Tests
Damit das Ergebnis eines A/B-Tests auch berücksichtigt werden kann, muss die Testvariante korrekt angezeigt werden und wie gewünscht funktionieren. Darstellungs- oder Funktionsfehler in Testvarianten machen die Testergebnisse wertlos und führen zu unzufriedenen Besuchern.
Relevante Browser für die Qualitätssicherung identifizieren
Testvarianten sollen in allen Kombinationen aus Browsern und Geräten funktionieren. Am besten schaut man aber nochmal im Webanalyse-Tool nach, welche am häufigsten vorkommen.
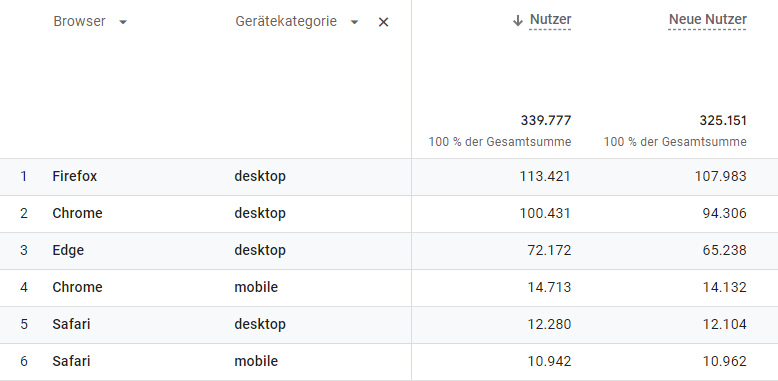
In GA4 unter Berichte > Nutzer > Technologie:
Die häufigsten Browser im GA4-Bericht
Basierend auf diesen Informationen erstellen wir eine Übersicht in Google Sheets:
Broswer-Übersicht in Google Sheets
(Die Liste der Browser kann für jeden Test die gleiche bleiben, da der Traffic der gleiche ist.)
Qualitätssicherung von Testvarianten: Anforderungen für Variante(n) definieren
Eine offensichtliche Anforderung an Testvarianten ist die korrekte Darstellung.
In vielen A/B-Tests wird jedoch nicht nur ein statisches Element eingefügt, sondern auch die Funktionalität der Website verändert. Beispiele sind:
nach Klick auf ein eingefügtes Element soll sich ein Layer oder eine neue Seite öffnen
ein sticky Element wird eingefügt
Produktbilder werden kleiner angezeigt, um anderen Elementen mehr Platz zu geben
Alle diese gewünschten Funktionalitäten müssen überprüft werden. Auch wichtig: Der Rest der Seite soll weiterhin wie bisher funktionieren.
Wir nehmen diese Anforderungen in unser Google Sheet auf:
Anforderungen für die Qualitätssicherung in Google Sheets
Eine weitere Komplikation ist die Abhängigkeit von bestimmten Faktoren wie
eingeloggte vs. nicht eingeloggte Besucher
B2C- vs. B2B-Ansicht
verschiedene Sprachen
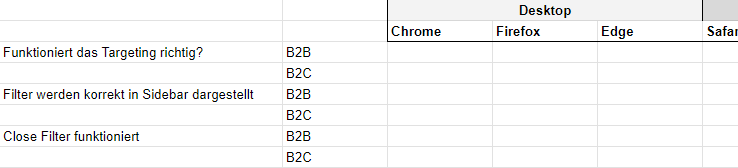
Gibt es solche Abhängigkeiten, fügen wir im Google Sheet eine weitere Spalte ein:
Erweiterte Anforderungen für die Qualitätssicherung in Google Sheets
Und werden in der Testvariante Besucheraktionen (wie Klicks auf Links) gemessen, dann nehmen wir auch dies in unsere Anforderungen auf. Falls Besucheraktionen bisher noch nicht gemessen werden, sollte das Tracking dazu spätestens mit dem Start des Tests aufgesetzt werden. Nur so kann man das Verhalten in der Testvariante, mit dem in der Kontrollvariante vergleichen.
Anforderungen je Testvariante systematisch überprüfen
Bei der tatsächlichen Qualitätssicherung braucht man vor allem eins: Sorgfältigkeit beim Überprüfen der zuvor definierten Anforderungen.
Wichtig: Nicht nur “ok” oder “nicht ok” in das Google Sheet eintragen, sondern beschreiben, was genau nicht funktioniert. Und einen Screenshot machen, den man an den Projektmanager weiterleiten kann.
Automatisierte Screenshots sind der einfachste und schnellste Weg, die korrekte Darstellung zu prüfen. Es gibt zahlreiche SaaS-Anbieter, die kostengünstig Screenshots aufnehmen. Zum Beispiel CrossBrowserTesting. Für einfache Tests ist dies eine sinnvolle Unterstützung, um viele Kombinationen auf einmal zu überprüfen.
Für etwas kompliziertere Tests muss man die Vorschau der Testvariante auf einem echten Gerät öffnen und prüfen.
Und falls nicht alle Geräte vorhanden sind, gibt es Anbieter (wie CrossBrowserTesting), bei denen man virtuelle Maschinen mit allen erdenklichen Kombinationen aus Browsern und Geräten fernsteuern kann.
5. Dokumentation von A/B-Tests: Auch nach Jahren noch wissen, was getestet wurde
Die Dokumentation von A/B-Tests hat viele verschiedene Funktionen
Die Dokumentation von A/B-Tests wird oft vernachlässigt. Dabei ist eine gründliche Dokumentation sehr wichtig für jeden, der langfristig testen möchte. Nur so kann man später auch wissen, was genau getestet wurde, wie, und mit welchem Ergebnis.
Die Dokumentation von A/B-Tests ist Grundlage für:
Briefings für Designer und Entwickler
Qualitätssicherung der Testvarianten
die Auswertung von Zwischenständen
die Vorstellung der Ergebnisse an Andere im Unternehmen
Diese Informationen sollte die Dokumentation von A/B-Tests enthalten
Der Grundsatz sollte sein: So dokumentieren und formulieren, dass andere auch nach Jahren noch verstehen und nachvollziehen können, was und warum getestet wurde.
Grundlegende Informationen
Wer ist Ansprechpartner (sowohl bei Kunden- als auch bei der Agentur)?
Laufzeit des Tests - inklusive Start- und Enddatum
Link zum Bericht im Testing-Tool
Gab es einen positiven Einfluss?
Metadaten, zum Beispiel verwendete Prinzipien, wie Verknappung
Executive Summary
Eine prägnante Zusammenfassung, insbesondere was getestet wurde, wie das Ergebnis lautet und was man gelernt hat.
Beispiel einer Executive Summary
Die Shop-Vorteile wurden als Aufzählung unter der Buy-Box angezeigt - Ergebnis: 10 % mehr Transaktionen (+27, 95 % statistisch signifikant). Shop-Vorteile überzeugen Nutzer zum Kauf.
Ausgangslage und Motivation
Weshalb wird der Test durchgeführt?
Anhand welcher Daten glaubt man, ein positives Ergebnis zu erzielen? (Zum Beispiel: Daten aus Google Analytics, Nutzerbefragungen, Webanalyse, Wettbewerbsanalyse, usw.)
Berechnungen, dass man statistisch signifikante Ergebnisse erreichen *kann*. Insbesondere, wie viele Besucher am Test teilnehmen werden und wie viele Conversions in den letzten 4 Wochen gemessen wurden
Test-Hypothese
Wenn X, dann Y, weil Z.
Beispiel einer TestHypothese
Wenn die Shop-Vorteile prominenter platziert werden, dann werden diese eher von Nutzern gesehen und können somit deren Verhalten beeinflussen, sodass Nutzer eher kaufen, weil sie die Shop-Vorteile überzeugen.
Auf welchen Seiten wird der Test ausgespielt? Und wie werden diese identifiziert? Zum Beispiel: auf allen Produktseiten, die über der Versandkostengrenze liegen.
Welche Besucher nehmen teil? Und wie werden diese identifiziert? Zum Beispiel: nur Desktop oder nur Mobile Nutzer, oder nur Nutzer, die eingeloggt sind.
Sehr wichtig hier: auch die technische Umsetzung des Targetings festhalten: z.B. die bestimmte dataLayer-Variable notieren, die verwendet wurde oder genaue Links zu Produktseiten, anstatt nur die Produktnamen.
Testvariante
Beschreibung der Testvariante(n) in Wörtern, um sofort deren Ziel zu verstehen - Wenn es mehrere Änderungen gibt, dann diese nummeriert festhalten, um einen guten Überblick zu behalten. Auch immer an die Funktionalität denken, zum Beispiel: bei neuen klickbaren Elementen das Linkziel notieren, sowie bei unterschiedlichen Ausprägungen der Testvariante, die Unterschiede klar definieren.
Screenshots der Testvariante(n), sowie der derzeitigen Website.
Ziele des A/B-Tests
Was wird gemessen, um den Erfolg zu beurteilen? Welches ist das Primärziel. Gibt es ein Sekundärziel? Wenn ja, welches?
In welchen Tools wird das Ziel gemessen?
Wie wird das Ziel gemessen (zum Beispiel wird der JavaScript-Code per Tag Manager ausgespielt oder wird das Ziel schon seit langer Zeit gemessen)?
Detaillierte Auswertung
Konkrete Zahlen und deren Interpretation in normaler Sprache
Für alle oben gemessenen Ziele
Inklusive Link zum Tool (wie Google Analytics), um die Zahlen später auch schnell aufrufen zu können
Erkenntnisse und nächste Schritte
Was hat man gelernt? Hat sich die Hypothese bewährt?
Wurde die Gewinnervariante umgesetzt? Und wie? (Per 100 % im Testing-Tool oder fest “im System”?)
Welche Nachfolgetests gibt es? Kann man die bewährte Hypothese erweitern und vielleicht auch auf anderen Seiten testen?
Dokumentation mit strukturierten Daten für einfache Auswertungen
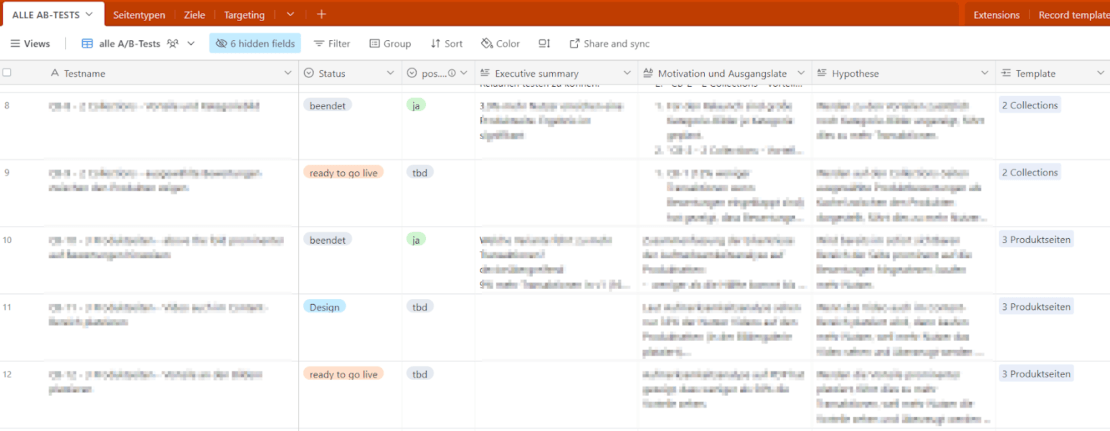
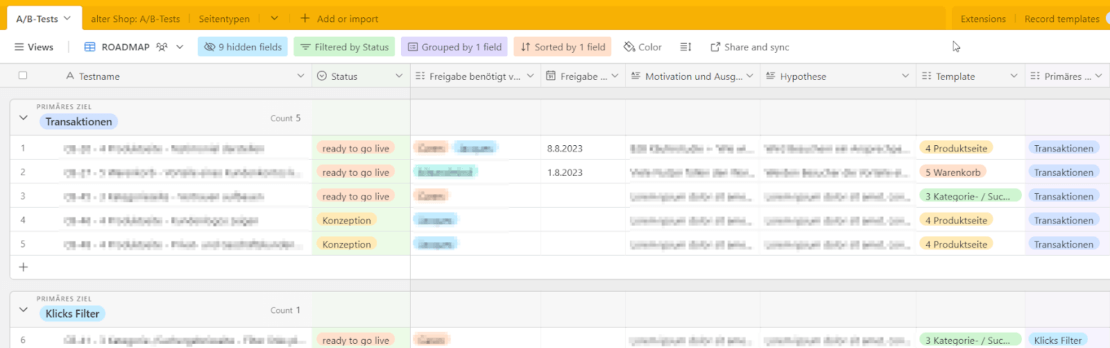
Wir verwenden für die Dokumentation all unserer A/B-Test eine No-Code-Datenbank (Airtable):
Im Bild sieht man einen Teil der Felder, die wir in Airtable zur Dokumentation verwenden.
Dokumentation von A/B-Tests in Airtable
Große Vorteile einer Datenbank gegenüber PowerPoint, Word oder Google Docs sind die strukturierten Informationen. Man kann mit wenig Aufwand Auswertungen durchführen und folgende Fragen beantworten:
Wie viele Tests mit positivem Einfluss gab es im letzten Quartal?
Auf welchen Seiten wurden im Quartal wie viele Tests durchgeführt?
Welche Prinzipien/Ansätze funktionieren, welche nicht?
Wie viele Tests sind in der Pipeline und können live gehen?
Gibt es Gewinnervarianten, die (noch) nicht umgesetzt wurden?
Wie lange laufen Tests im Durchschnitt?
Im Gegensatz zu Google Sheets oder Excel kann man in Airtable auch Dateien (wie Screenshots der Testvarianten) integrieren.
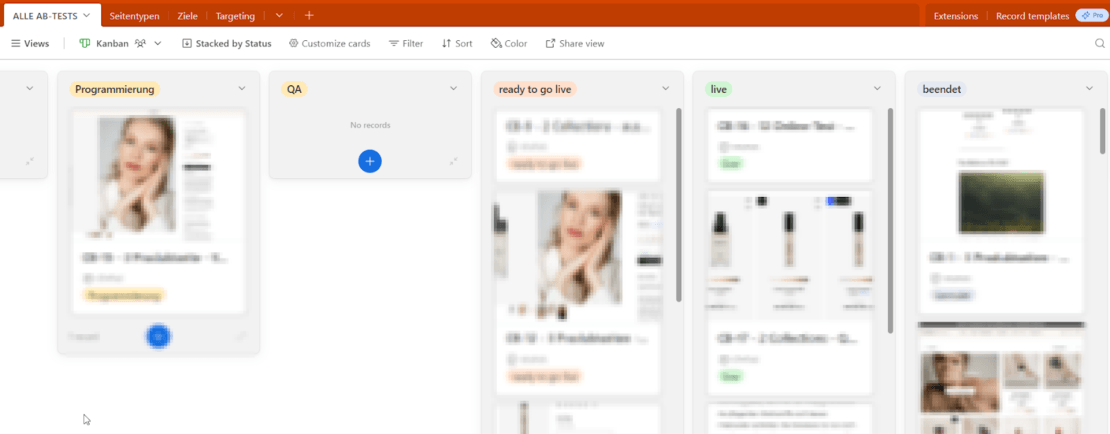
Außerdem kann man sich ein Kanban-Board erstellen und auch das Projektmanagement direkt in Airtable abbilden:
Projektmanagement von A/B-Tests in Airtable
Für das Präsentieren von Ergebnissen vor Stakeholdern oder im Quartalsreview kann man sich aus den strukturierten Daten automatisch PDFs oder PowerPoint-Präsentationen erstellen lassen.
6. A/B-Tests korrekt auswerten und sicherstellen, dass Ergebnisse tatsächlich aussagekräftig sind
Wichtigste Frage: Ist die Veränderung nicht nur zufällig?
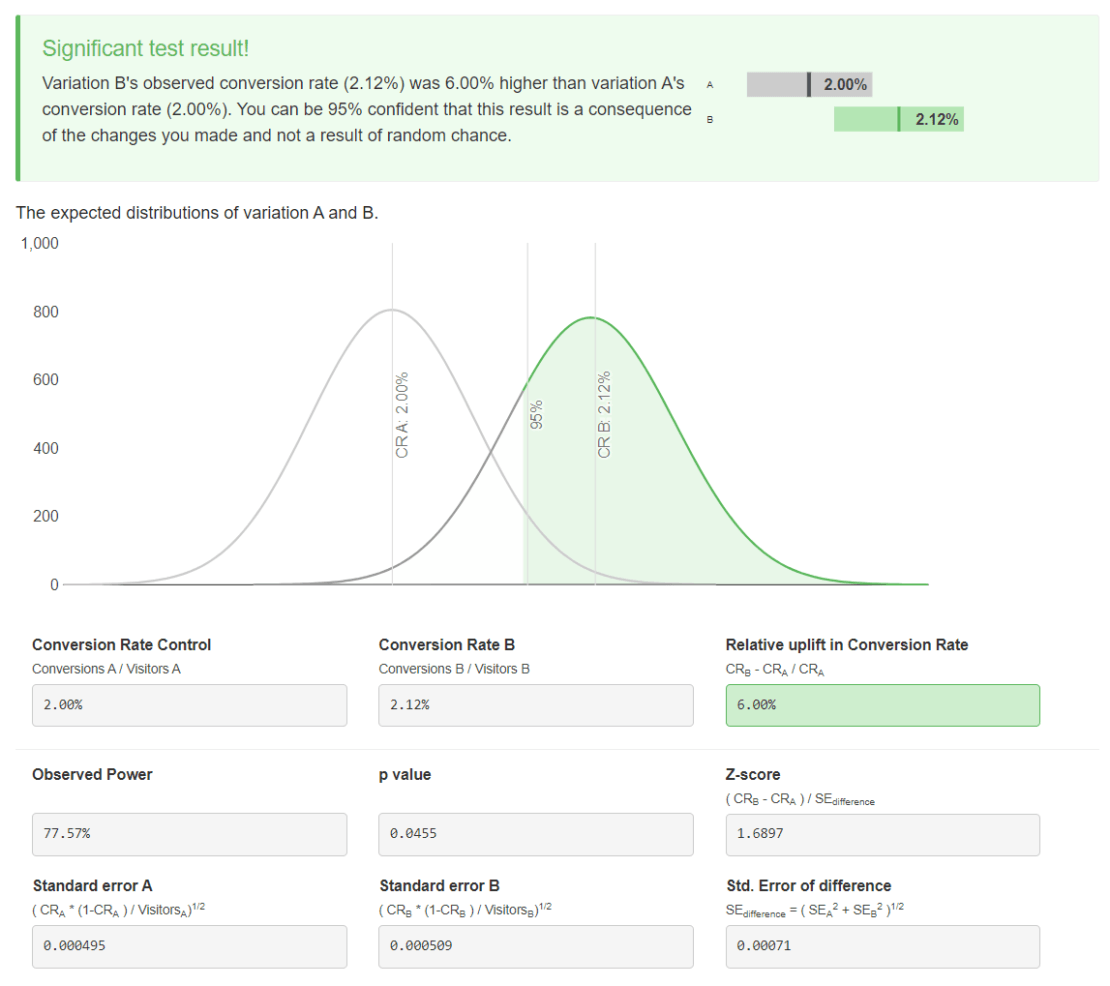
Die wichtigste Auswertung eines A/B-Tests lautet: Ist der gemessene Einfluss während des Experiments nur zufällig? Oder wird die Conversion-Rate auch höher sein, wenn die Gewinnervariante für alle Besucher ausgespielt wird?
Statistische Signifikanz ist die Antwort auf diese Frage. Jedoch nicht mit einem klaren Ja/Nein, sondern in Form von Wahrscheinlichkeiten. Und da es bei A/B-Tests nicht um lebenswichtige Entscheidungen geht, legt man sich meistens auf ein Konfidenzniveau von 95 % fest. Das heißt, in einem von 20 Fällen gibt es einen False Positive. Es wurde ein Einfluss gemessen, obwohl es diesen gar nicht gibt.
Fast alle Testing-Tools bieten eingebaute Berechnungen der statistischen Signifikanz.
Testergebnisse in ABlyft
Gibt es diese nicht, kann man auf Onlinetools wie den A/B-Test-Rechner von abtestguide.com zurückgreifen. Dort kann man sowohl den p-Wert als auch den z-Score berechnen.
Analyse der Testergebnisse in ABTestGuide inklusive Signifikanz, p-Wert und z-Score
Auswertung von A/B-Tests mit weiteren Metriken
Zusätzlich zur primären Metrik (häufig Transaktionen oder Leads) sollte man auch Mikro-Conversions messen und deren statistische Signifikanz ansehen.
Vielleicht hat eine Testvariante keinen Einfluss auf die eigentliche Conversion (Transaktion), aber auf einen Schritt weiter vorne (Checkout angefangen). Dann kann man in einem Nachfolgetest versuchen, diese weitere Hürde zu meistern.
Sie bieten eine Art Rückversicherung. Angenommen, es wird die Position der Filter auf Kategorieseiten getestet. Hat sich die Anzahl der Klicks auf die Filter nicht erhöht, ist es unwahrscheinlich, dass die Änderung einen positiven Einfluss auf die Anzahl der Transaktionen hat.
Damit diese Auswertungen funktionieren, muss man sich schon vor dem Start des Tests um das entsprechende Tracking kümmern.
Auswertung der Testvariante nach Segmenten
Nach diesen Segmenten sollte man Testergebnisse unterscheiden
Desktop vs. Mobile
Bestandskunden vs. Neukunden
Traffic-Quellen / Kampagnen
Einstieg auf Produktseite vs. auf Kategorieseite
Für welche Produktkategorien funktioniert die Testvariante besser?
Häufig sind diese Segmente im Testing-Tool nicht verfügbar. Die Auswertung muss daher im Webanalyse-Tool erfolgen.
Wichtig für GA4
In den Explorativen Datenansichten verwendet GA4 nur Annäherungen von Metriken wie Besucher oder Conversions. Sollen auch kleine Einflüsse zuverlässig erkannt werden, muss die Auswertung in BigQuery erfolgen.
A/B-Testergebnisse durchgehen: Interpretation der Daten, Erkenntnisse und Nachfolgetests
Die wichtigste Frage lautet natürlich: Wurde die Hypothese bestätigt?
Zusätzlich sollten Erkenntnisse notiert werden. Dazu gehört insbesondere die Frage, ob das angepasste/eingefügte Element Einfluss auf die Conversion-Rate hat. Wenn beispielsweise zwei Tests der Produktbilder keinen Einfluss hatten, sollten sich die nächsten Tests mit anderen Elementen/Themen beschäftigen.
Auch Herausforderungen, die bei der Implementierung aufgekommen sind, sollten notiert werden. War zum Beispiel das Targeting problematisch oder gab es Probleme mit der Darstellung bei bestimmten Produktkategorien, hilft dies bei weiteren Tests.
Im nächsten Schritt gilt es dann, Nachfolgetests zu definieren. Hat eine alternative Darstellung der Produktbewertungen gut funktioniert, sollten hier weitere Tests gefahren werden. Gleiche gilt für Prinzipien wie “Vertrauen kommunizieren”. Hat dieses einen positiven Einfluss, sollte es auf eine andere Art weiterentwickelt werden.
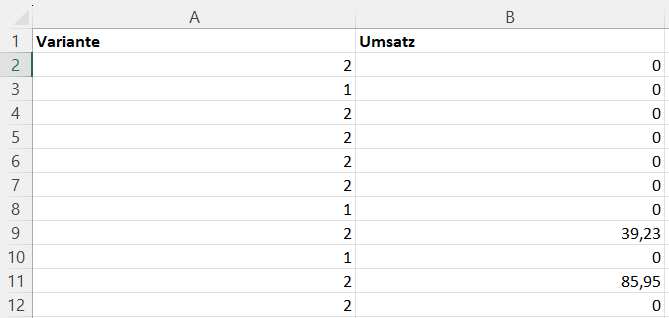
Spezielle Herausforderung bei der Auswertung von A/B-Tests: Warenkorbwert
Conversion-Rate ist eine binäre Metrik: Ein Besucher kauft oder nicht.
Der Warenkorbwert verhält sich anders. Insbesondere gibt es dafür keine Normalverteilung. Die oben genannten Berechnungen der Signifikanz funktionieren nicht.
Statt nur der Anzahl der Nutzer und Conversions je Testvariante benötigt man ausführlichere Daten zu Käufen und Warenkörben auf Nutzerebene, die man zum Beispiel aus GA4 exportiert:
7. Projektmanagement, agile Roadmap und korrekte Priorisierung
Agile Roadmap verwenden, um Anzahl der A/B-Tests zu maximieren
Das Ziel eines Testing-Programms sollte es sein, immer mindestens einen (sinnvollen) Test aktiv zu haben. So verschenkt man kein Potenzial, die Conversions zu optimieren und neue Erkenntnisse zu gewinnen.
Theoretisch kann man das ganze nächste Jahr planen. In der Praxis werden solche Pläne aber schnell über den Haufen geworfen. Es muss auf ein Release gewartet werden, eine Freigabe war nicht rechtzeitig da oder Tests auf einem Seitentyp haben überhaupt keinen Einfluss.
Statt Tests Monate im Voraus zu planen, stellen wir sicher, dass je Optimierungsziel ca. 2-3 Tests startklar sind. So kann direkt nach Ende eines Tests der nächste starten. Gleichzeitig laufende Tests sollten unterschiedliche Optimierungsziele haben, denn nur so kann man sicherstellen, durch welchen Test der Uplift oder Downlift zustande kam.
Wir verwenden hierfür die gleiche Airtable-Datenbank wie zur Dokumentation der A/B-Tests. Dort erstellen wir einfach eine neue Ansicht, wie diese:
Dokumentation der anstehenden A/B-Tests in Airtable
Tipps, um A/B-Tests rechtzeitig startklar zu haben
Von der Testidee zum startklaren Test ist es ein weiter Weg. Vor allem Abstimmungen mit anderen Beteiligten können länger als erwartet dauern, und zu Verzögerungen führen.
Ein gutes und aktives Projektmanagement ist deshalb Pflicht. Es braucht eine zentrale Person, die alles zusammenhält:
Roadmap / Liste der startbereiten Tests aktualisiert halten.
Sich frühzeitig um Freigaben kümmern. (Wir halten auch dies in Airtable fest. Siehe Screenshot oben)
Allen Beteiligten (wie Entwicklern und Grafikern) realistische Fristen setzen. (Am besten im Projektmanagement-Tool)
Nach Ablauf der Frist (automatisch) nachhaken.
Außerdem ist es sinnvoll, auch einfachere Tests voranzutreiben. Insbesondere mit weniger Programmieraufwand und weniger internem Diskussionsbedarf. Einfache Tests sollten nicht unterschätzt werden, denn diese können oft einen überraschenden Einfluss auf die Conversion-Rate haben.
Und am besten beziehen sich die Tests nicht aufeinander, bzw. sind nicht auf das gleiche Thema fokussiert. Angenommen, alle startklaren Tests beziehen sich auf die Produktbewertungen. Stelle sich heraus, dass die Darstellung der Produktbewertungen keinen Einfluss auf die Conversion-Rate hat, dann sind die startklaren Tests nicht vielversprechend. Besser: Voneinander unabhängige Tests planen.
Richtige Priorisierung von mehreren A/B-Tests
Natürlich möchte man Tests mit dem größten Potenzial zuerst testen. Wir ziehen dafür diese Faktoren zur Hilfe:
Wie hoch ist der Aufwand (für Grafik, Programmierung, interne Freigaben/Überzeugung)?
Wie hoch ist der erwartete Einfluss?
Der zweite Punkt ist schwer einzuschätzen. Wenn man den Einfluss kennen würde, müsste man nicht testen. Wir beantworten deshalb diese Fragen:
Gibt es eine Änderung im sofort sichtbaren Bereich?
Gibt es eine große Änderung?
Wird der Test durch Webanalyse-Daten untermauert?
Wird der Test durch Umfrageergebnisse, Session Recordings oder die Auswertung von Kundenbewertungen untermauert?
Basiert der Test auf einem zuvor erfolgreichen Ansatz?